
All of my opinions are italicized and sources are in blue.
Sora can generate videos up to a minute long while maintaining visual quality and adherence to the user’s prompt.
Today, Sora is becoming available to red teamers to assess critical areas for harms or risks. We are also granting access to a number of visual artists, designers, and filmmakers to gain feedback on how to advance the model to be most helpful for creative professionals.
We’re sharing our research progress early to start working with and getting feedback from people outside of OpenAI and to give the public a sense of what AI capabilities are on the horizon.
Sora is able to generate complex scenes with multiple characters, specific types of motion, and accurate details of the subject and background. The model understands not only what the user has asked for in the prompt, but also how those things exist in the physical world.
The model has a deep understanding of language, enabling it to accurately interpret prompts and generate compelling characters that express vibrant emotions. Sora can also create multiple shots within a single generated video that accurately persist characters and visual style.
The current model has weaknesses. It may struggle with accurately simulating the physics of a complex scene, and may not understand specific instances of cause and effect. For example, a person might take a bite out of a cookie, but afterward, the cookie may not have a bite mark.
The model may also confuse spatial details of a prompt, for example, mixing up left and right, and may struggle with precise descriptions of events that take place over time, like following a specific camera trajectory.
Safety
We’ll be taking several important safety steps ahead of making Sora available in OpenAI’s products. We are working with red teamers — domain experts in areas like misinformation, hateful content, and bias — who will be adversarially testing the model.
We’re also building tools to help detect misleading content such as a detection classifier that can tell when a video was generated by Sora. We plan to include C2PA metadata in the future if we deploy the model in an OpenAI product.
In addition to us developing new techniques to prepare for deployment, we’re leveraging the existing safety methods that we built for our products that use DALL·E 3, which are applicable to Sora as well.
For example, once in an OpenAI product, our text classifier will check and reject text input prompts that are in violation of our usage policies, like those that request extreme violence, sexual content, hateful imagery, celebrity likeness, or the IP of others. We’ve also developed robust image classifiers that are used to review the frames of every video generated to help ensure that it adheres to our usage policies, before it’s shown to the user.
We’ll be engaging policymakers, educators and artists around the world to understand their concerns and to identify positive use cases for this new technology. Despite extensive research and testing, we cannot predict all of the beneficial ways people will use our technology, nor all the ways people will abuse it. That’s why we believe that learning from real-world use is a critical component of creating and releasing increasingly safe AI systems over time.
As reported by HowToGeek,
Google has been rapidly updating its Gemini AI, previously known as Google Bard, over the past few months. Today, the company revealed an updated Gemini 1.5 model currently in testing, with the ability to process more information at once and use videos as input.
Google has revealed Gemini 1.5, an updated version of the model that currently powers the Gemini chatbot and other AI features and services. It’s currently only available in preview for software developers and enterprise customers, but it will presumably roll out to the Gemini chatbot in the near future.
The main promised improvement is a significantly larger “token context window”—the data that can be input information in the AI prompt. Gemini 1.5 Pro has a standard 128,000 token context window, a significant leap from the 32,000 token limit in Gemini 1.0. Google is allowing a limited group of developers and companies to use context windows of up to 1 million tokens, which is enough for one hour of video, 11 hours of audio, or over 700,000 words. Google said it also successfully tested a 10 million token limit.
Google said in a blog post, “[Gemini] 1.5 Pro can perform highly-sophisticated understanding and reasoning tasks for different modalities, including video. For instance, when given a 44-minute silent Buster Keaton movie, the model can accurately analyze various plot points and events, and even reason about small details in the movie that could easily be missed.”
The updated Gemini model is also supposedly better at “understanding and reasoning tasks,” outperforming the earlier 1.0 Pro model in 87% of the benchmarks Google uses to test large language models. That still leaves room for Gemini AI to create incorrect data, like every other generative AI solution, so it remains an imperfect solution for data analysis and facts.
Google didn’t confirm when the regular Gemini chatbot and other Google services will be updated to use Gemini 1.5, but the company did say that “significant improvements in speed are also on the horizon,” so Google might be waiting for that before rolling it out to all users. The new model is available in preview for developers and enterprise customers using AI Studio and Vertex AI.
As reported by Ars Technica,
On Tuesday, OpenAI announced that it is experimenting with adding a form of long-term memory to ChatGPT that will allow it to remember details between conversations. You can ask ChatGPT to remember something, see what it remembers, and ask it to forget. Currently, it’s only available to a small number of ChatGPT users for testing.
So far, large language models have typically used two types of memory: one baked into the AI model during the training process (before deployment) and an in-context memory (the conversation history) that persists for the duration of your session. Usually, ChatGPT forgets what you have told it during a conversation once you start a new session.
Various projects have experimented with giving LLMs a memory that persists beyond a context window. (The context window is the hard limit on the number of tokens the LLM can process at once.) The techniques include dynamically managing context history, compressing previous history through summarization, links to vector databases that store information externally, or simply periodically injecting information into a system prompt (the instructions ChatGPT receives at the beginning of every chat).
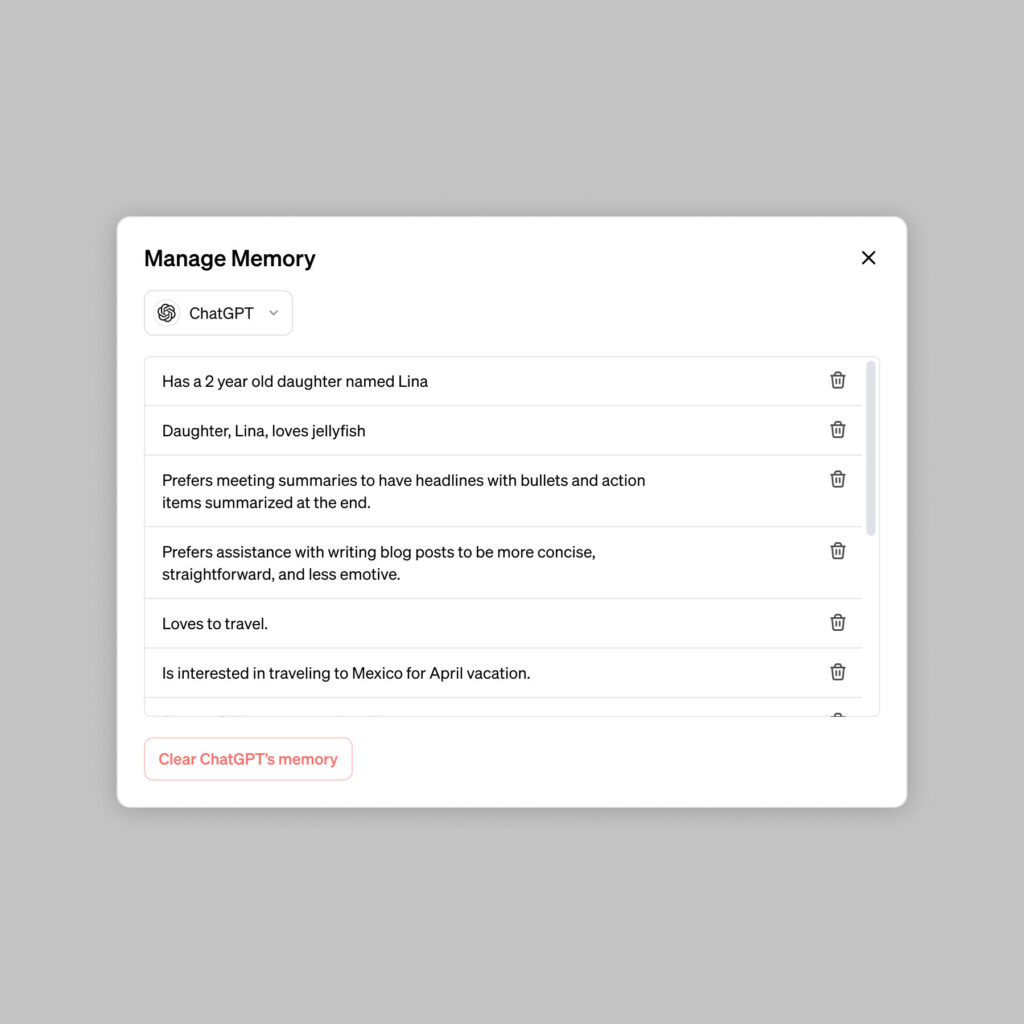
OpenAI hasn’t explained which technique it uses here, but the implementation reminds us of Custom Instructions, a feature OpenAI introduced in July 2023 that lets users add custom additions to the ChatGPT system prompt to change its behavior.
Possible applications for the memory feature provided by OpenAI include explaining how you prefer your meeting notes to be formatted, telling it you run a coffee shop and having ChatGPT assume that’s what you’re talking about, keeping information about your toddler that loves jellyfish so it can generate relevant graphics, and remembering preferences for kindergarten lesson plan designs.
Also, OpenAI says that memories may help ChatGPT Enterprise and Team subscribers work together better since shared team memories could remember specific document formatting preferences or which programming frameworks your team uses. And OpenAI plans to bring memories to GPTs soon, with each GPT having its own siloed memory capabilities.
Users will also be able to control what ChatGPT remembers using a “Manage Memory” interface that lists memory items. “ChatGPT’s memories evolve with your interactions and aren’t linked to specific conversations,” OpenAI says. “Deleting a chat doesn’t erase its memories; you must delete the memory itself.”
ChatGPT’s memory features are not currently available to every ChatGPT account, so we have not experimented with it yet. Access during this testing period appears to be random among ChatGPT (free and paid) accounts for now. “We are rolling out to a small portion of ChatGPT free and Plus users this week to learn how useful it is,” OpenAI writes. “We will share plans for broader roll out soon.”
As reported by Ars Technica,
Apple’s iMessage service is not a “gatekeeper” prone to unfair business practices and will thus not be required under the Fair Markets Act to open up to messages, files, and video calls from other services, the European Commission announced earlier today.
Apple was one of many companies, including Google, Amazon, Alphabet (Google’s parent company), Meta, and Microsoft to have its “gatekeeper” status investigated by the European Union. The iMessage service did meet the definition of a “core platform,” serving at least 45 million EU users monthly and being controlled by a firm with at least 75 billion euros in market capitalization. But after “a thorough assessment of all arguments” during a five-month investigation, the Commission found that iMessage and Microsoft’s Bing search, Edge browser, and ad platform “do not qualify as gatekeeper services.” The unlikelihood of EU demands on iMessage was apparent in early December when Bloomberg reported that the service didn’t have enough sway with business users to demand more regulation.
Had the Commission ruled otherwise, Apple would have had until August to open its service. It would have been interesting to see how the company would have complied, given that it provides end-to-end encryption and registers senders based on information from their registered Apple devices.
Google had pushed the Commission to force Apple into “gatekeeper status,” part of Google’s larger campaign to make Apple treat Android users better when they trade SMS messages with iPhone users. While Apple has agreed to take up RCS, an upgraded form of carrier messaging with typing indicators and better image and video quality, it will not provide encryption for Android-to-iPhone SMS, nor remove the harsh green coloring that particularly resonates with younger users.
Apple is still obligated to comply with the Digital Markets Act’s other implications on its iOS operating system, its App Store, and its Safari browser. The European Union version of iOS 17.4, due in March, will offer “alternative app marketplaces,” or sideloading, along with the tools so that those other app stores can provide updates and other services. Browsers on iOS will also be able to use their own rendering engines rather than providing features only on top of mobile Safari rendering. Microsoft, among other firms, will make similar concessions in certain areas of Europe with Windows 11 and other products.

cheese
👍