
As reported by Ars Technica,
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It also announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Copilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not qualify as “open source” because that term has a specific meaning in software, and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Meta trained both models on two custom-built, 24,000-GPU clusters. In a podcast interview with Dwarkesh Patel, Meta CEO Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in was that it was going to asymptote more, but even by the end it was still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
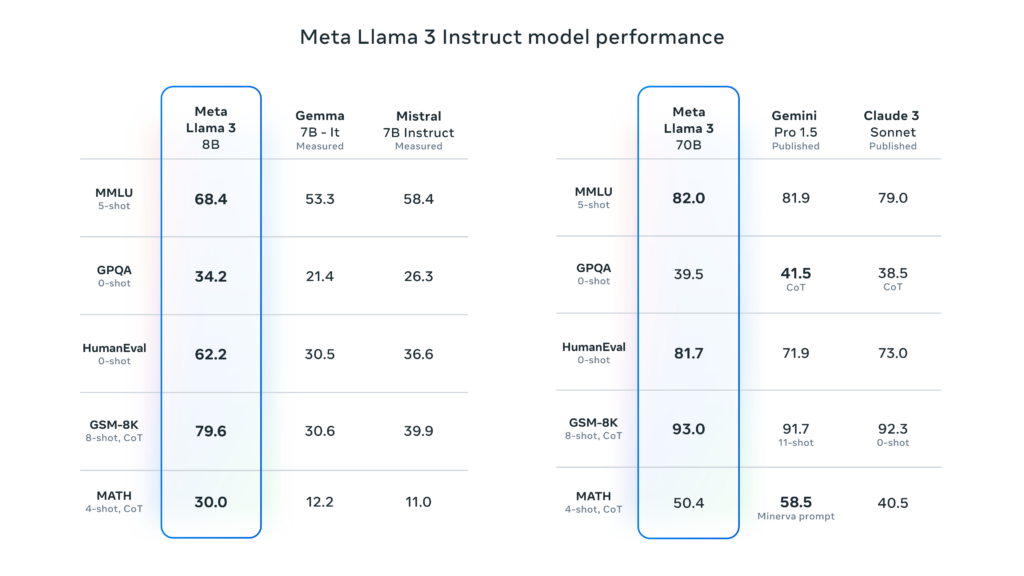
Meta also announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model also held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will also support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Also on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company also announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.
As reported by The Verge,
Tesla has issued a recall for every Cybertruck it’s delivered to customers due to a fault that’s causing the vehicle’s accelerator pedal to get stuck.
According to the National Highway Traffic Safety Administration (NHTSA) on Wednesday, the defect can result in the pedal pad dislodging and becoming trapped in the vehicle’s interior trim when “high force is applied.”
The fault was caused by an “unapproved change” that introduced “lubricant (soap)” during the assembly of the accelerator pedals, which reduced the retention of the pad, the recall notice states. The truck’s brakes will still function if the accelerator pedal becomes trapped, though this obviously isn’t an ideal workaround.
The recall impacts “all Model Year (‘MY’) 2024 Cybertruck vehicles manufactured from November 13, 2023, to April 4, 2024,” with the fault estimated to be present in 100 percent of the total 3,878 vehicles. This is essentially every Cybertruck delivered to customers since its launch event last year.
A recall seemed to be inevitable after Cybertruck customers were reportedly notified earlier this week that their deliveries were being delayed, with at least one owner being informed by their vehicle dealership that the truck was being recalled over its accelerator pedal. The issue was also highlighted by another Cybertruck owner on TikTok, showing how the fault “held the accelerator down 100 percent, full throttle.”
The timeline reported in the NHTSA filing says that Tesla was first notified of the defective accelerator pedals on March 31st, followed by a second report on April 3rd. The company completed internal assessments to find the cause on April 12th before voluntarily issuing a recall. As of Monday this week, Tesla said it isn’t aware of any “collisions, injuries, or deaths” attributed to the pedal fault.
Tesla is notifying its stores and service centers of the issue “on or around” April 19th and has committed to replacing or reworking the pedals on recalled vehicles at no charge to Cybertruck owners. Any trucks produced from April 17th onward will also be equipped with a new accelerator pedal component and part number.
This is actually the second of Tesla’s many recalls to affect the Cybertruck, but it is the most significant. The company issued a recall for 2 million Tesla vehicles in the US back in February due to the font on the warning lights panel being too small to comply with safety standards, though this was resolved with a software update.
Tesla fans have taken issue with the word “recall” in the past when the company has proven adept at fixing its problems through over-the-air software updates. But they likely will have to admit that, in this case, the terminology applies.
As reported by Gizmodo,
Kids in Texas are taking state-mandated standardized tests this week to measure their proficiency in reading, writing, science, and social studies. But those tests aren’t going to necessarily be graded by human teachers anymore. In fact, the Texas Education Agency will deploy a new “automated scoring engine” for open-ended questions on the tests. And the state hopes to save millions with the new program.
The technology, which has been dubbed an “auto scoring engine” (ASE) by the Texas Education Agency, uses natural language processing to grade student essays, according to the Texas Tribune. After the initial grading by the AI model, roughly 25% of test responses will be sent back to human graders for review, according to the San Antonio Report news outlet.
Texas expects to save somewhere between $15-20 million with the new AI tool, mostly because fewer human graders will need to be hired through a third-party contracting agency. Previously, about 6,000 graders were needed, but that’s being cut down to about 2,000, according to the Texas Tribune.
A presentation published on the Texas Education Agency’s website appears to show that tests of the new system revealed humans and the automated system gave comparable scores to most kids. But a lot of questions remain about how the tech works exactly and what company may have helped the state develop the software. Two education companies, Cambium and Pearson, are mentioned as contractors at the Texas Education Agency’s site but the agency didn’t respond to questions emailed Tuesday.
The State of Texas Assessments of Academic Readiness (STAAR) was first introduced in 2011 but redesigned in 2023 to include more open-ended essay-style questions. Previously, the test contained many more questions in the multiple choice format which, of course, was also graded by computerized tools. The big difference is that scoring a bubble sheet is different from scoring a written response, something computers have more difficulty understanding.
In a sign of potentially just how toxic AI tools have become in mainstream tech discourse, the Texas Education Agency has apparently been quick to shoot down any comparisons to generative AI chatbots like ChatGPT, according to the Texas Tribune. And the PowerPoint presentation on the Texas Education Agency’s site appears to confirm that unease with comparisons to anything like ChatGPT.
“This kind of technology is different from AI in that AI is a computer using progressive learning algorithms to adapt, allowing the data to do the programming and essentially teaching itself,” the presentation explains. “Instead, the automated scoring engine is a closed database with student response data accessible only by TEA and, with strict contractual privacy control, its assessment contractors, Cambium and Pearson.”
As reported by Forbes,
A federal data privacy law has remained elusive for years. But a pair of Washington lawmakers are taking their shot at getting legislation over the finish line. Rep. Cathy McMorris Rodgers and Senator Maria Cantwell have yet to formally introduce their bill, the American Privacy Rights Act, but have released a discussion draft. A formal introduction is expected later this month. The proposal would limit what data companies can collect and use as well as create consumer data rights, including the right to sue companies for privacy violations.
Significantly, the legislation would preempt existing state laws and establish a national standard, though state attorneys general would be responsible for enforcement along with the Federal Trade Commission. A patchwork of state regulations has emerged in recent years, some of which have been pushed by the business community, as Politico explains. However, the tech industry’s preference has remained a national standard to ease the compliance challenge of meeting the different state-level rules. Notably, the law would end the FTC’s data privacy rulemaking, which the agency has pursued in the absence of legislation to create some new federal rules.
Sponsorship of the legislation by McMorris Rodgers and Cantwell is significant because they lead the committees of jurisdiction in the House and Senate, respectively. The best chance in recent years, back in 2022, faltered partly due to Cantwell’s opposition, The Washington Post reported. That legislation, the American Data Privacy and Protection Act, cleared the House Energy and Commerce Committee, which McMorris Rodgers now chairs, in a 53-2 vote. However, the bill never received a vote on the House floor as then-Speaker Nancy Pelosi (D-Calif.) issued a statement expressing concern it would weaken California’s data privacy regulations. These worries about preemption could be an issue again for lawmakers, particularly Democrats, whose home states have more stringent rules.
While Cantwell’s buy-in is a step toward passage, the bill does not appear to be on a fast track to becoming law. According to Punchbowl News, the ranking members in both the House and Senate — Rep. Frank Pallone and Senator Ted Cruz — were not closely involved in the drafting process. Pallone stated that he was encouraged by the proposal but is seeking several changes. Per a Forbes staff report, Cruz has taken a more negative stance, saying that while he is still reviewing the bill, he will not back a proposal that allows consumers to sue for privacy violations or empowers the FTC, which are common complaints among Republicans. Cruz’s resistance threatens to sink the legislation before it even has a real opportunity to get off the ground.
The bill is expected to go through regular order, meaning committee hearings and markups in both chambers. This process will be lengthy and likely stretch past the August recess, which could mean its best chance of passage is during the lame duck session at the end of this year. If this timing does happen, the bill will likely have to be noncontroversial enough to be attached to a must-pass measure, such as appropriations legislation or the annual National Defense Authorization Act.
McMorris Rodgers will likely push hard to get this proposal over the line as she is retiring at the end of the session and seeking as many legislative victories as possible before leaving. She was also a lead sponsor on the bill restricting data brokers’ ability to sell to foreign adversary countries and entities based in those countries, which passed the House in a 414-0 vote. That proposal may have a better chance at being signed into law but its fate in the Senate is uncertain. It also is viewed as being more closely linked to the bill that could result in a TikTok ban than this federal data privacy bill.
Even amid this renewed federal push for data privacy legislation, states continue to act. Most recently, the Maryland Legislature passed two data privacy bills: one restricting how companies can collect and use personal data and one creating more stringent regulations for users younger than 18, based on California’s Age-Appropriate Design Code Act. Maryland Governor Wes Moore still needs to sign the proposals to become law and has not publicly indicated his stance. The legislation has garnered significant opposition from the tech industry, and legal challenges are possible if Moore does approve the bills.
Other state lawmakers will likely closely monitor this effort in Maryland as it is the first data privacy bill modeled after the ADPPA. If this stricter standard does become law and survives any court challenges, it could provide a template for other state lawmakers looking to impose tougher rules. Of course, it will not matter if McMorris Rodgers and Cantwell’s bill becomes the law of the land, but that is a risky bet.
As reported by engadget,
In addition to updating its developer guidelines to allow music streaming apps to link to external websites, Apple has also added new terms that allow game emulators on the App Store. The updated guidelines, first noticed by 9to5Mac, now say that retro gaming console emulator apps are welcome and can even offer downloadable games. Apple also reportedly confirmed to developers in an email that they can create and offer emulators on its marketplace.
Emulator software wasn’t allowed on the App Store prior to this update, though developers have been finding ways to distribute them to iOS users. To be able to install them, users usually need to resort to jailbreaking and downloading sideloading tools or unsanctioned alternate app stores first. This rule update potentially eliminates the need for users to go through all those lengths and could bring more Android emulators to iOS.
Apple warns developers, however, that they “are responsible for all such software offered in [their] app, including ensuring that such software complies with these Guidelines and all applicable laws.” Clearly, allowing emulators on the App Store doesn’t mean that it’s allowing pirated games, as well. Any app offering titles for download that the developer doesn’t own the rights to is a no-no, so fans of specific consoles will just have to hope that their companies are planning to release official emulators for iOS. While these latest changes to Apple’s developer guidelines seem to be motivated by the EU’s Digital Markets Act regulation, which targets big tech companies’ anti-competitive practices, the new rule on emulators applies to all developers worldwide.
